4月中旬,华为公布了AI基础设施架构的新进展,推出了全球最大规模超节点——基于昇腾 910C 打造的 CloudMatrix 384。我们援引了SemiAnalysis对此的数据和分析,并将其主要内容在后文分享。从中,我们窥见了中国AI可能的叙事变化:
①从单兵到集群,互联的重要性凸显:受限于先进制程与HBM,昇腾910C难以在单卡性能上同英伟达Blackwell匹敌,但凭借强大的通讯互联技术积累,华为实现了系统级的创新和领先;②基于国家资源禀赋的创新:超大规模集群的代价是巨大功耗,但中国能源网络的发达程度为全球之最,相较于北美高昂的能源成本,中国能源的比较优势得以发挥。
一、华为CM384与NVL72对比
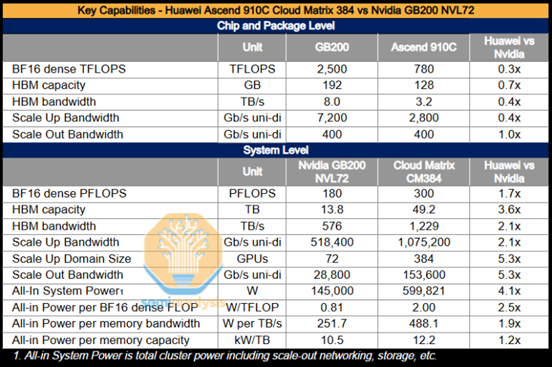
华为CloudMatrix 384 由 384 块 Ascend 910C 芯片组成,通过全对全拓扑结构连接。其背后的思路很简单:虽然每块GPU 性能仅为Nvidia Blackwell 的三分之一,但五倍于NVL72的Ascend数量弥补了系统级的性能差距。完整的CloudMatrix 系统现在甚至可以提供300 PFLOP 的 BF16 计算能力,几乎是 GB200 NVL72 的两倍。凭借超过3.6 倍的总内存容量和2.1 倍的内存带宽,中国现在可能拥有超越Nvidia 的AI 系统能力。
其唯一的缺点是,它需要4.1 倍 GB200 NVL72 的功率,每 FLOP 的功率差 2.5 倍,每 TB/s 内存带宽的功率差 1.9 倍,每 TB HBM 内存容量的功率差 1.2 倍。
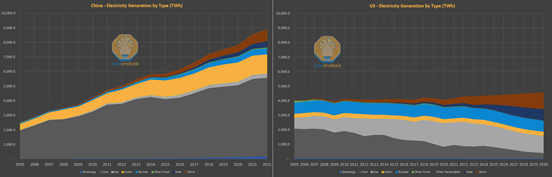
但能耗对中国并不是一个核心的限制因素。中国拥有最大的太阳能、水电和风电装机容量,目前在核电部署方面也处于领先地位,而美国仅维持着上世纪70年代部署的核电规模。中国自2011年以来,新增的电网容量已相当于整个美国电网规模。
二、系统级互联的构建
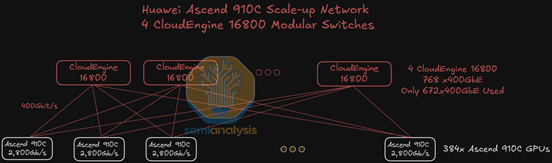
不同Nvidia,华为SuperPod的Scale Up互联采用了去铜全光的方案。每个GPU用7个400G LPO Sipho光模块提供的2800Gbit/s带宽来实现Scale Up互联,合计384张GPU一共通过4个CloudEngine Switch的单层扁平拓扑实现互联。
Scale Up所用LPO光模块用量合计达5376只。从GPU侧出发,一共有384张GPU*7个LPO模块/张=2688个LPO光模块。Switch侧的用量与GPU侧一对一匹配,也是2688只LPO光模块。
但是,5000余个光模块用于扩展规模将引发可靠性问题,且需要高质量的容错训练软件来应对如此多的光模块。此外,假设每个400G LPO光模块成本~200美元、功耗~0.5W,那么超级节点的扩展网络的TCO大约会是NVL72机架的8倍,功耗则将达到后者的10倍。
2.Scale Out:
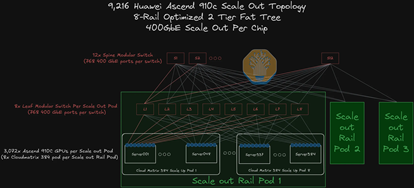
在Scale Out网络,CM384采用了二层优化拓扑。Leaf层,每个Leaf Switch拥有768个400G光模块端口,其中384个端口向下连接到384张GPU,向上的384个端口连接到Spine Switch。Spine层,每个Spine Switch匹配GPU的数量是Leaf Switch的0.5倍。
因此Scale Out互联中,每个SuperPod一共将用到384*1(GPU侧)+384*2(Leaf侧)+384*2*0.5(Spine侧)=1536只光模块。
综合两部分的估算可以得到,在整个CM384的系统级互联中,每个CloudMatrix Pod的LPO光模块总用量达到了惊人的6912只。
三、单卡构成的拆解
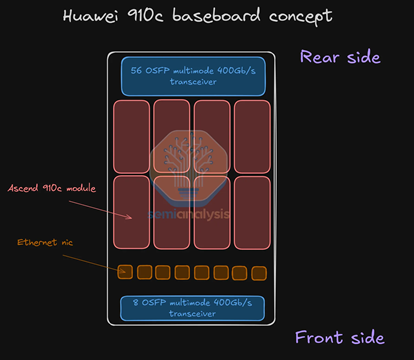
为保障巨大的系统级互联得以实现,每张基板上均需要大量的互联元件。单张基板合计8张910C GPU、2张鲲鹏CPU、8张Thor-2后端网卡、8*7只Scale Up 400G LPO光模块(每张GPU对应7只)、1*8只Scale Out 400G LPO光模块、2张200G前端网卡及2个前端200G光模块。
由于制程和HBM限制,910C单卡性能仅有Nvidia GB200的三分之一。但超大规模的集群弥补了单兵作战能力的不足,基于强大的通信技术积累,华为用互联弥补了算力的缺口。
四、结论
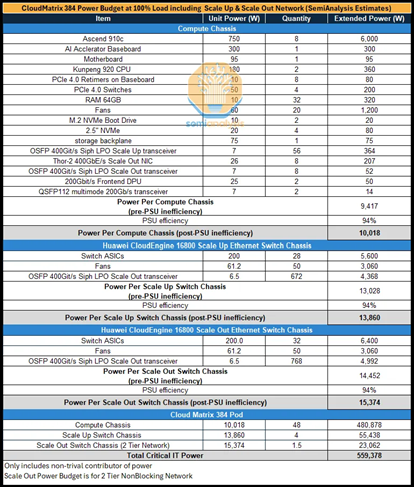
Semi Analysis对整个CloudMatrix384系统的功耗进行了详细估计。由于纵向扩展与横向扩展网络大规模采用光模块,整个包含384张GPU的集群功耗极高。即便采用了功耗更低的线性直驱LPO光模块方案,总功耗仍然令人吃惊。单个CM384超节点功耗超500千瓦,是英伟达GB200 NVL72机架的4倍以上。但同时,整个超节点也提供了超出NVL72超节点70%的算力。
我们认为,一方面,半导体产业系统性瓶颈导致的制程和先进芯片问题可以通过系统级互联来弥补(无论是基于全光方案,还是基于铜),对算力不足问题实现“曲线救国”。另一方面,额外的费用和电力是中国为了追平西方的计算能力所需的必要成本,相较于国家安全和AI竞争身位的重要性,能源的代价对中国相对更低。
基于强大互联能力的技术优势,和基于国家禀赋的能源优势,将在未来扩大数据中心节点规模和速度的过程中,成为中国公司可利用的关键要素。
https://semianalysis.com/2025/04/16/huawei-ai-cloudmatrix-384-chinas-answer-to-nvidia-gb200-nvl72/




{kind=link}